3次元点集合データ(ポイントクラウド)の解析¶
この文章で解説するのは
- 3次元の点データからパーシステント図を計算する
- その図をパラメータを変えながら可視化する
- テキストデータにbirth-death pairを出力する
- 基本的な逆解析(birth simplex, death simplexの出力)を行う
の4つです。ここまではおよそどのようなポイントクラウドデータでも 共通ですので、ここまでできるようになると良いでしょう。
version 3.0 以降に関する注意¶
推奨される出力ファイルの識別子が .idiagram から .pdgm に変更になりました.内部フォーマットも変更されています.
パーシステント図の計算¶
対称となるデータは pointcloud.txt というファイルです。これは
3次元標準正規分布に従うランダムな点を
5000個撒き散らしたものです。これを解析してみましょう。
まずこれを表示します。最初の10行を見てみましょう
head pointcloud.txt
-1.688604987600753837e+00 5.699006029198190326e-01 -1.346186823505619579e+00 1.087144905453914845e+00 1.934202933045750861e+00 8.273916713882594198e-01 -1.157236831361657392e-01 -1.168206946858528328e+00 -3.994263428990901810e-01 -1.602174172538033403e-01 -8.626762802439005284e-01 1.188676117430170320e+00 5.613694793886953027e-02 -8.925811823166075465e-01 7.867005084945112303e-01 -3.121247358971382946e-01 -2.982206113960411131e-01 1.317235943833295453e+00 9.831752257585583132e-01 -2.465116319438791059e+00 -6.081245384492277584e-01 -7.600677459838747207e-01 -6.142993053684995264e-01 3.828101574633524518e-01 3.666431208906655304e-01 -4.606251408481700227e-01 1.759186989342665930e+00 3.009754635114507137e-01 5.049945721030327794e-01 1.429650286762043088e+00
このようにデータが3列で並んでいます
データからパーシステント図を計算します。 python3 -m homcloud.pc_alpha というコマンドを使います。
利便性のため、homcloud-pc-alphaというコマンドもあり、これも同じ動作をします。
python3 -m homcloud.pc_alpha -d 3 pointcloud.txt pointcloud.pdgm
とします。すると pointcloud.pdgm というファイルが生成されます。これが
パーシステント図の情報を収めたファイルです。-d 3というのが入力データの次元
(ここでは3)で、pointcloud.txt で入力データを、pointcloud.pdgmで出力データを
指定します。
パーシステント図の可視化¶
次に、ここからパーシステント図をプロットしてみましょう。
python3 -m homcloud.plot_PD -d 1 pointcloud.pdgm -o pointcloud-pd1.png
とします。ここで-d 1というのは1次のパーシステント図(つまりリングの情報)を
可視化することを意味します。-d 2とすると2次のパーシステント図(つまり空隙の情報)を
可視化します。-o pointcloud-pd1.pngは画像を出力先のファイル名を指定します。すると以下のような画像が出力されます。
ここで使っている display は jupyter notebookでbashを使うときに画像を表示するためのインターフェースです。 jupyter notebookと組み合わせると便利なのでこのチュートリアルでは使っていきます。
display < pointcloud-pd1.png

左下のほうに何かちょっと見えてあとは何も見えません。というのは
このデータは左下のほうにデータ(birth-death pair)が偏っているからです。
そこで色付けを log scale にしましょう。-l オプションを使います。あとX軸とY軸のスケールが違うのはかっこ悪いのでそれも直します。
こちらは --aspect equal です。
python3 -m homcloud.plot_PD -d 1 -l --aspect equal pointcloud.pdgm -o pointcloud-pd1-log.png
display < pointcloud-pd1-log.png

基本的にはパーシステント図の点は対角線から離れるほど「意味のある」リング構造と対応し、 またY軸が大きい値になるほど大きなリング構造を表しています。 つまり(0.5, 0.7)のあたりにある点がこのランダムな点がなすリング構造のなかで最も ちゃんとしたリング構造を持っているものと対応していると言えそうです。
ここで注意しておくと、パーシステント図のX、Y軸は点に貼り付ける球の半径と対応していると
よくある教科書には書かれています。HomCloudでは実はこれは半径の2乗が使われています。
つまり√0.5≒0.7と√0.7≒0.84が実際の半径になります。これは主には内部のアルゴリズムの都合に
よるものですが、各点に重みづけをしたときにはこのほうが自然に見えるという事情もあり、
HomCloudでは2乗の値が使われます。これを止めたいときはパーシステント図を
homcloud.pc_alpha で計算するときに --no-square オプションを付けると
半径パラメータそのものがX、Y軸に現れます。
さて、次にbirth-death pairが集中している
左下の 0.0〜0.1 のあたりを拡大して調べてみましょう。デフォルトでは
すべてのbirth-death pairが含まれるような範囲でプロットするので、これを変更します。
このときは以下のようなコマンドを使います。-xオプションで範囲を指定します。
python3 -m homcloud.plot_PD -d 1 -l -x "[0:0.1]" --aspect equal pointcloud.pdgm -o pointcloud-pd1-zoomup.png
display < pointcloud-pd1-zoomup.png

もちろんランダムデータですので意味のあるリング構造があるわけでは ないのですが、ランダムだとこういうヒストグラムの分布が見えるんだなあ、というのは 知っておくと役に立ちます。
-Xオプションで解像度を変えることができます。デフォルトでは
128x128でヒストグラムを描きますが、もっと細かく256x256にしてみましょう。
以下のコマンドです。
python3 -m homcloud.plot_PD -d 1 -l -x "[0:0.1]" -X 256 --aspect equal pointcloud.pdgm -o pointcloud-pd1-zoomup.png
display < pointcloud-pd1-zoomup.png

ここでは画像を保存してdisplayで表示していましたが、matplotlib (pythonのプロットライブラリ)のインタラクティブインターフェスも
使えることを覚えておくと良いです。-o ...による出力ファイル指定を削るとウィンドウが表示されます。
これは右上に x=... y=... というのが表示されていてマウスカーソルがパーシステント図のどの座標の位置にあるのかを
表示してくれたりします。
また、plot_PD_guiというモジュールもあり、これはより高度なインタラクティブGUIを提供します。ここで説明したような
プロットのパラメータ変更などがインタラクティブにできます。以下のようにして起動します。
python3 -m homcloud.plot_PD_gui -d 1 pointcloud.pdgm
Attribute Qt::AA_EnableHighDpiScaling must be set before QCoreApplication is created.
テキストデータでの解析¶
次にパーシステント図をテキストデータとして出力してみましょう。 計算したパーシステント図をさらに統計処理したい、といった場合には テキスト出力をしてそれを使うのが手軽です。以下のコマンドです。
# データの行数が多いので最後の10行だけを tail で表示する
python3 -m homcloud.dump_diagram -S no -d 1 pointcloud.pdgm | tail
0.5973638046166524 0.6105533327957627 0.5652198460841742 0.6333196314607091 0.5906213675656147 0.6399900554981125 0.6442572283186025 0.6455006374894877 0.6619166403896363 0.6636272756594286 0.6716352526485909 0.6731624171711277 0.4845143271980769 0.6955406657117916 0.699242025096557 0.6994652025551098 0.7400408653215168 0.7484476418235964 0.7997505082496258 0.800028497810961
すると2列の数値データが出力されます。これは1次のbirth-death pairすべてを列挙していて、
左側の数値がbirth time、右側の数値がdeath timeです。これも
半径の2乗の値が出力されます。-d 1の所を-d 2にすると2次のbirth death pairが
出力されます。-S noは後で説明します
さて、実際に利用するときにはファイルに保存したいでしょうから、-oオプションを使って以下のように
やってみましょう。すると pointcloud-pd1.txt に1次のbirth-death pairの情報がテキストで保存されます。
python3 -m homcloud.dump_diagram -S no -d 1 pointcloud.pdgm -o pointcloud-pd1.txt
python3 -m homcloud.dump_diagram -S yes -d 1 pointcloud.pdgm -o pointcloud-pd1.txt
# head で最初の3行だけ表示している
head -n 3 pointcloud-pd1.txt
0.0005037159143533377 0.0005579705552885796 ((0.9509954988275516,-1.0068450361062282,0.5444291481244738),(0.9578267519847968,-1.0257637674912665,0.5845574329183165)) ((0.9509954988275516,-1.0068450361062282,0.5444291481244738),(0.9491853165615161,-1.0446271794013047,0.5530720162883241),(0.9578267519847968,-1.0257637674912665,0.5845574329183165)) 0.0009259080093991961 0.0009586588306071996 ((-0.28508278742529314,0.18171712515275223,0.11312983987397246),(-0.33924144759564706,0.1933836037205496,0.08794323938926972)) ((-0.28508278742529314,0.18171712515275223,0.11312983987397246),(-0.3409101402063031,0.16848605635352581,0.09550916713739144),(-0.33924144759564706,0.1933836037205496,0.08794323938926972)) 0.0010596423596121558 0.001129414564220647 ((0.5526278710732792,0.6042269908917515,-0.5658452971742082),(0.5738152766437832,0.5718181805421756,-0.5135066661702851)) ((0.5526278710732792,0.6042269908917515,-0.5658452971742082),(0.5738152766437832,0.5718181805421756,-0.5135066661702851),(0.5712305433890057,0.6264996091243692,-0.5476846170921237))
これの最初の2列はbirth time、death timeです。次の2つの列
(よく見ると、{...} {...}という形をしています)
がそれぞれbirth simplex、death simplexです。
これの最初の行は(0.0005037159143533377, 0.0005579705552885796)というbirth death pairに
対応するリング構造は、
(0.950995498828,-1.00684503611,0.544429148124)
(0.957826751985,-1.02576376749,0.584557432918)の2つの点を結んだ辺が「現れた」タイミングで生じ、
(0.950995498828,-1.00684503611,0.544429148124)
(0.949185316562,-1.0446271794,0.553072016288)
(0.957826751985,-1.02576376749,0.584557432918)の3つの点を頂点とする3角形が「現れた」タイミングで消えたことを意味します。
上で上げたサーベイ論文が理解の助けになるでしょう。特に実際的なデータ解析では
death simplexのほうが重要です。death simplexの重心あたりがリング構造の
中心になることが多いと考えられるためです。この出力結果は
ファイルpointcloud-pd1.txtに保存されていますのででそれをさらに解析することでリングの空間分布を調べる
ようなこともできます。
display < pointcloud-pd1-log.png

(0.5, 0.7) 付近に birth-death pair があります。これは
対角線から離れているため、他のリングに比べて重要度が高そうです。これ
の optimal volume を調べましょう。homcloud.optimal_volume モジュールを使います。
以下のようなコマンドを実行します。-d 1で次数を、-x 0.5 -y 0.7でbirth-death pairの位置を
指定します。位置を精密に指定しなくとも、指定した点に一番近いpairを探索してそのpairのoptimal volumeを計算します。
-Pは内部的にparaviewコマンドを使って可視化をすることを指定します。
python3 -m homcloud.optvol -d 1 -x 0.5 -y 0.7 -P pointcloud.pdgm
するとparaviewのウィンウドウが表示されたはずです。左側のパネルの「Apply」ボタンを押すと表示がされます。 緑のリングが対象となるリングです。それ以外にも様々な情報が表示されています。
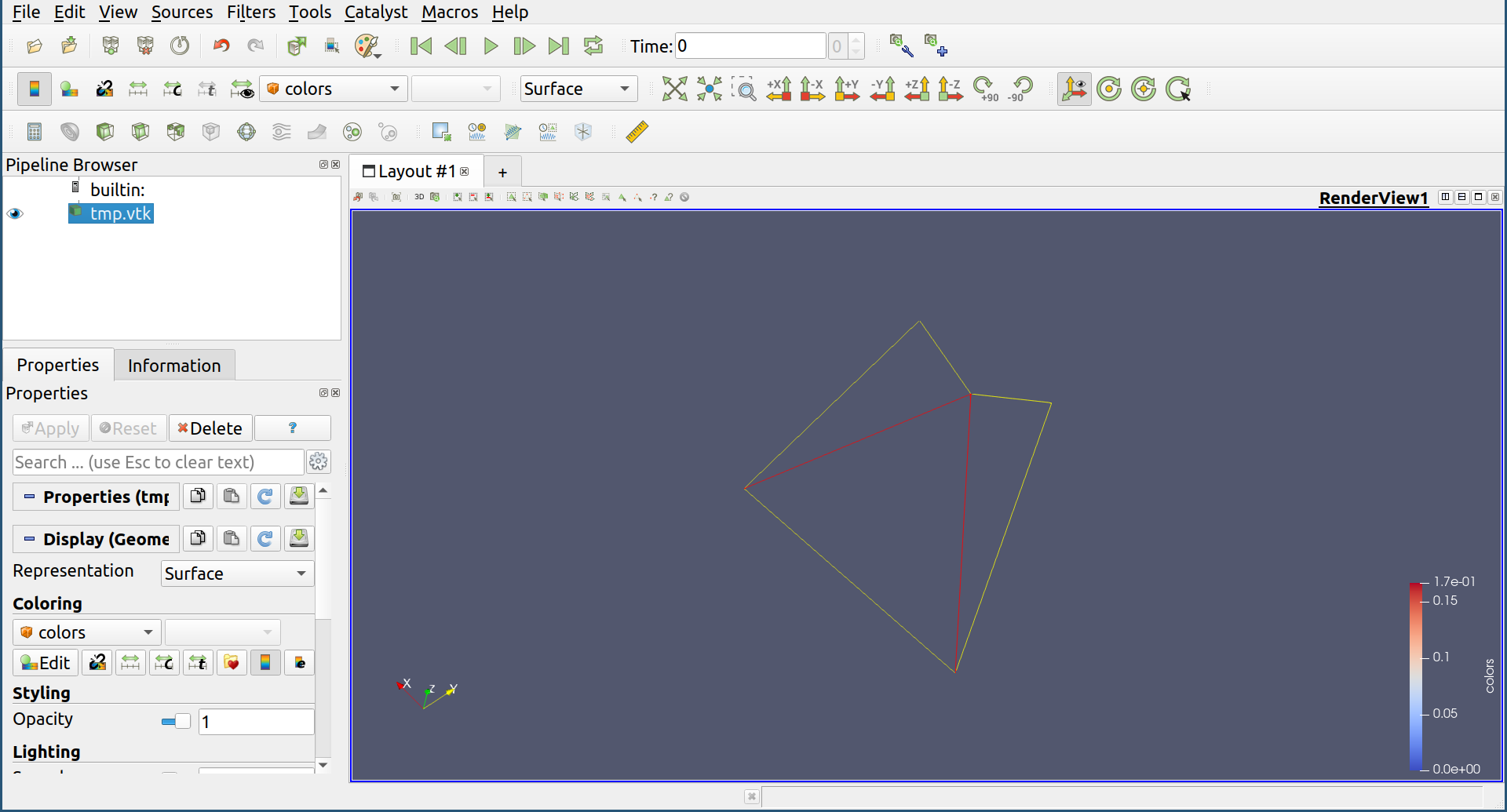
この情報は ファイルに保存することもできます。以下のようにします。
python3 -m homcloud.optvol -d 1 -x 0.5 -y 0.7 -j optimal_volume.json pointcloud.pdgm
optimal_volume.jsonにoptimal volumeの情報が保存されています。
これはjson formatになっていて様々な情報が保存されています。
このファイルの中身については現在ドキュメントを準備中です。
とりあえずは大林に質問してください。
optimal volumeとbirth/death simplexの使い分けですが、optimal volumeのほうが情報量が多いので普段はこちらを使えばよいでしょう。 ただ、optimal volumeは計算コストが大きいので、入力データのサイズが大きい場合や多くのbirth-death pairで計算したい場合で 計算時間がどうしようもなくなったら birth/death simplexの利用を検討すると良いでしょう。
以上でこのチュートリアルは終わりです。お疲れさまでした。